
Processes are prone to failures during the execution of the system. A failure can be defined as a deviation from correct behavior [HT94], i.e. a behavior that does not comply with its specification. More specifically, a fault is a flaw in the system that originates from a node, which may cause unexpected behavior and result in an error. If the error is not handled and then propagates through the system, it can lead to a failure. 2.2 illustrates the steps of a failure in a distributed system.
Failures can happen due to algorithm conception and programming (which can be difficult to detect, especially in distributed algorithms as processes can be at different steps of the execution of the algorithm), hardware, or hacking. A process which fails during the execution of the system is considered to be faulty, whereas a process which never fails during the whole execution of the system is correct.
There exist different modes of process failures in the literature. In addition, failures can be
permanent, where a component stays in the faulty state forever, transient, where a component is in the
faulty state for a finite duration, or intermittent, where a component successively exhibits correct and
faulty behavior [Dub11]. Failures can be classified from the weak to the strongest one, i.e. a failure
includes previous failures and is a subset of the next failures [Ber04; GR06; CGR11; Cal15;
Cam20].
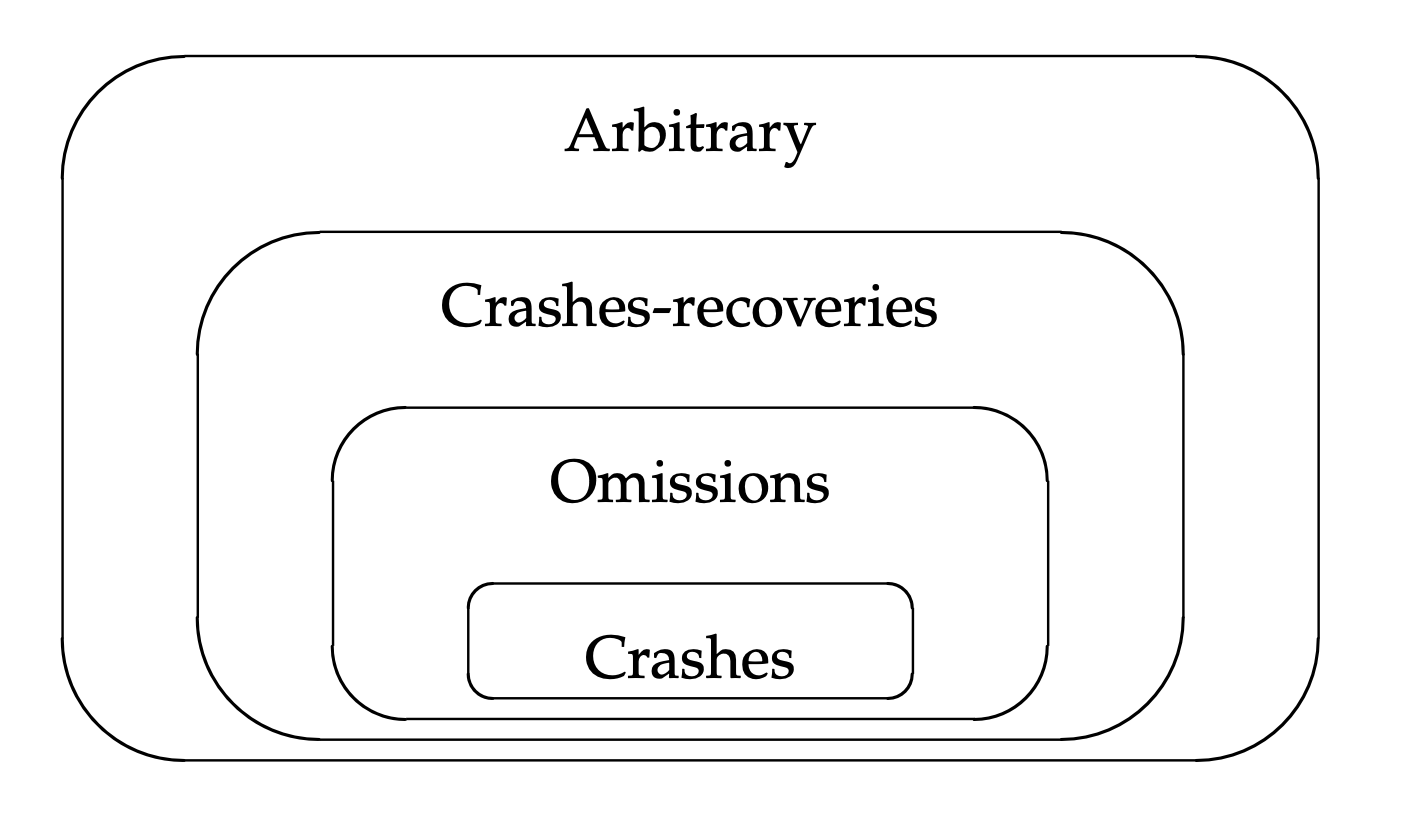
As shown in 2.3, crash failures are included in omission failures, which are included in crash-recovery
failures, which are included in arbitrary failures.
Crash: it leads to a definitive and permanent halt of the process execution, meaning that the process has stopped and will not execute any further steps of its algorithm (fail-silent).
Before the failure, the process behaves correctly, but when the failure arises, the process is considered shutdown and will not come back in the system.
If the system is not asynchronous, other processes may be able to detect its state, by not receiving any response from this process when invocation messages are repeatedly sent to it. However, this crash failure detection mechanism relies on the use of timeouts, which is a period of time a process has for something to occur (assuming synchrony assumptions).
The different modes of process failure are summarized in 2.2. Note that this list is not exhaustive and there exist other failures, such as fail-safe, fail-stop, authenticated byzantine, etc.
|
|
|
|||
| Crash | Process | Permanent halt of process. | |||
| Omission | Process | Temporary halt of process. | |||
| Fail-recovery | Process | Halt of process execution, but may recover and resume afterwards. | |||
| Arbitrary/Byzantine | Process | Arbitrarily omits step or reply, sets or return wrong value. | |||